Today at USV, we are hosting our 4th semiannual Trust, Safety and Security Summit. Brittany, who manages the USV portfolio network, runs about 60 events per year — each one a peer-driven, peer-learning experience, like a mini-unconference on topics like engineering, people, design, etc. The USV network is really incredible and the summits are a big part of it.
I always attend the Trust, Safety and Security summits as part of my policy-focused work. Pretty much every network we are investors in has a “trust and safety” team which deals with issues ranging from content policies (spam, harassment, etc) to physical safety (on networks with a real-world component), to dealing with law enforcement. We also include security here (data security, physical security) here — often managed by a different team but with many overlapping issues as T&S.
What’s amazing to witness when working with Trust, Safety and Security teams is that they are rapidly innovating on policy. We’ve long described web services as akin to governments, and it’s within this area where this is most apparent. Each community is developing its own practices and norms and rapidly iterating on the design of its policies based on lots and lots and lots of real-time data.
What’s notable is that across the wide variety in platforms (from messaging apps like Kik, to marketplaces like Etsy and Kickstarter, to real-world networks like Kitchensurfing and Sidecar, to security services like Cloudflare and Sift Science), the common element in terms of policy is the ability to handle the onboarding of millions of new years per day thanks to data-driven, peer-produced policy devices — which you could largely classify as “reputation systems”.
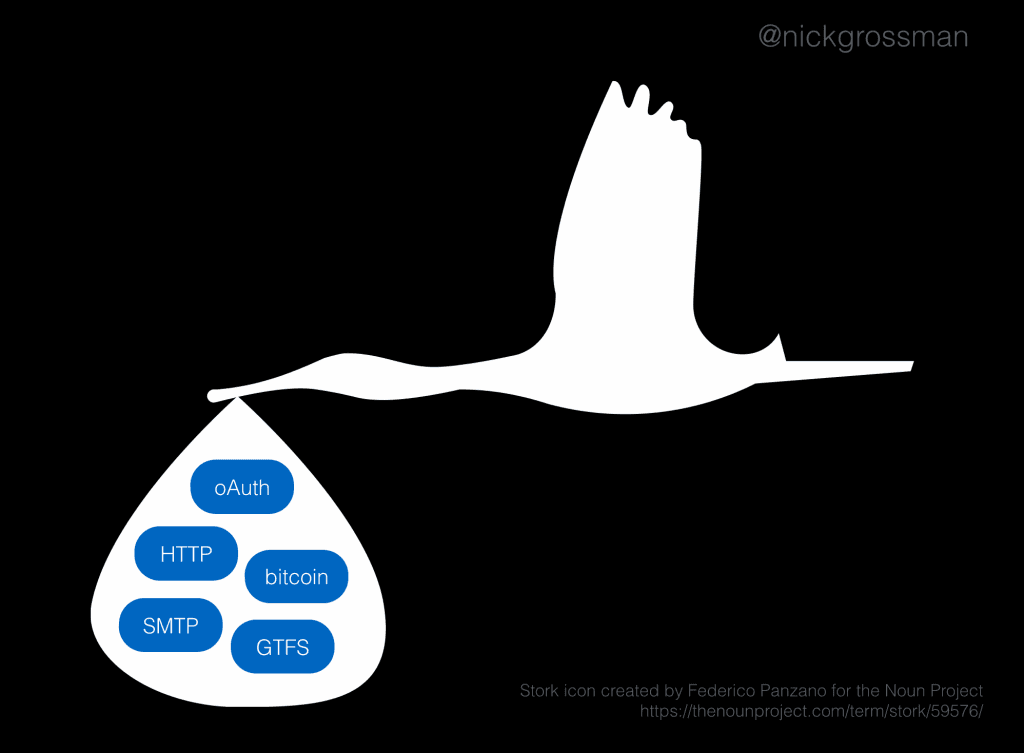
Note that this approach works for “centralized” networks like the ones listed above, as well as for decentralized systems (like email and bitcoin) and that governing in decentralized systems has its own set of challenges.
This is a fundamentally different regulatory model than what we have in the real world. On the internet, the model is “go ahead and do — but we’ll track it and your reputation will be affected if you’re a bad actor”, whereas with real-world government, the model is more “get our permission first, then go do”. I’ve described this before as “regulation 1.0” vs. “regulation 2.0”:
I recently wrote a white paper for the Data-Smart City Solutions program at the Harvard Kennedy School on this topic, which I have neglected to blog about here so far. It’s quite long, but the above is basically the TL;DR version.
I mention it today because we continue to be faced with the challenge of applying regulation 1.0 models to a regulation 2.0 world.
Here are two examples:
First, the NYC Taxi and Limousine commission’s recently proposed rules for regulating on-demand ride applications. At least two aspects of the proposed rules are really problematic:
TLC wants to require their sign off on any new on-demand ride apps, including all updates to existing apps.
TLC will limit any driver to having only one active device in their car
On #1: apps ship updates nearly every day. Imagine adding a layer of regulatory approval to that step. And imagine that that approval needs to come from a government agency without deep expertise in application development. It’s bad enough that developers need Apple’s approval to ship iOS apps — we simply cannot allow for this kind of friction when bringing products to market.
On #2: the last thing we want to do is introduce artificial scarcity into the system. The beauty of regulation 2.0 is that we can welcome new entrants, welcome innovations, and welcome competition. We don’t need to impose barriers and limits. And we certainly don’t want new regulations to entrench incumbents (whether that’s the existing taxi/livery system or new incumbents like Uber)
Anti money laundering requirements are improved but vague.
A requirement that new products be pre-approved by the NYDFS superintendent.
Custody or control of consumer funds is not defined in a way that takes full account of the technology’s capabilities.
Language which could prevent businesses from lawfully protecting customers from publicly revealing their transaction histories.
The lack of a defined onramp for startups.
Without getting to all the details, I’ll note two big ones, which are DFS preapproval for all app updates (same as with TLC) and the “lack of a defined on-ramp for startups”.
This idea of an “on-ramp” is critical, and is the key thing that all the web platforms referenced at the top of this post get right, and is the core idea behind regulation 2.0. Because we collect so much data in real-time, we can vastly open up the “on-ramps” whether those are for new customers/users (in the case of web platforms) or for new startups (in the case of government regulations).
The challenge, here, is that we ultimately need to decide to make a pretty profound trade: trading up-front, permission-based systems, for open systems made accountable through data.
The challenge here is exacerbated by the fact that it will be resisted on both sides: governments will not want to relinquish the ability to grant permissions, and platforms will not want to relinquish data. So perhaps we will remain at a standoff, or perhaps we can find an opportunity to consciously make that trade — dropping permission requirements in exchange for opening up more data. This is the core idea behind my Regulation 2.0 white paper, and I suspect we’ll see the opportunity to do this play out again and again in the coming months and years.
I’ve spent the better part of the last six years thinking about where web standards come from. Before joining USV, I was at the (now retired) urban tech incubator OpenPlans, where, among other things, we worked to further “open” technology solutions, including open data formats and web protocols.
The two biggest standards we worked on were GTFS, the now ubiquitous format for transit data, including routes, schedules and real-time data for buses and trains; and Open311, an open protocol for reporting problems to cities (broken streetlights, potholes, etc) and asking questions (how do I dispose of paint cans?). Each has its own origin story, which I’ll get into a little bit below.
Last week, I wrote about “venture capital vs. community capital” (i.e., the “cycle of domination and disruption“) — and really the point of that talk was the relationship between proprietary platforms and open protocols. My point in that post was that this tension is nothing new; in fact it is a regular part of the continuous cycle of the bundling and unbundling of technologies, dating back, well, forever.
Given the emergence of bitcoin and the blockchain as an application platform, it feels like we are in the midst of another wave of energy and effort around the development and deployment of web standards. So we are seeing a ton of new open standards and protocols being imagined, proposed, and developed.
The key question to be asking at this moment is not “what is the perfect open standard”, but rather, “how do these things come to be, anyway?”
Joi Ito talks about the Internet as “a belief system” as much as a technology, and part of how I interpret that is the fact that it rests on the idea of everyone just agreeing to do things kind of the same way. So, we don’t all need to run the same computers, use the same ISP, or be members of a common club (social network) — rather, all we need to do is adhere to some common protocols (HTTP, SMTP, etc). No one owns the protocols (by and large) — they are more like “customs” than anything else. It works because we all agree to do more or less the same thing.
So when we’re looking at all these new protocols appearing (from openname, to ethereum, to whatever), the question is not just “is this a good idea” but rather “how might everyone agree to do this?”. It’s a political and social problem as much as a technical problem. And more often than not, there is some sort of “magic” involved that is the difference between “cool idea” or “nice whitepaper” and “everyone does it this way”.
Here is a crack at bucketing a few of the major strategies I’ve observed for bringing standards to market. (These are not necessarily mutually exclusive, and are certainly not complete — would love to find other patterns and examples.)
Update: The Old Fashioned Way
Max Bulger makes a good point on Twitter that I have neglected here to include the traditional, formal methods of developing web standards — though standards bodies like the w3c and the IETF. That’s how many standards get made, but not all. For this post, I want to focus on hacks to that traditional process.
The Brute Force Approach
One way to bring a standard to market is to simply force it in, using your market position as leverage. Apple has been doing this for decades, most recently with USB-C, two decades ago with the original USB.
Word on the street is that USB-C was less of a consensus-driven standards body project and more of an apple hand off. Time will tell, but now that USB-C is the port to beat all ports in the Macbook 12, it could become the single standard for laptop and mobile/tablet ports. You can do this if you’re huge (see also: Microsoft and .doc, Adobe and .pdf)
The Happy Magnet Approach
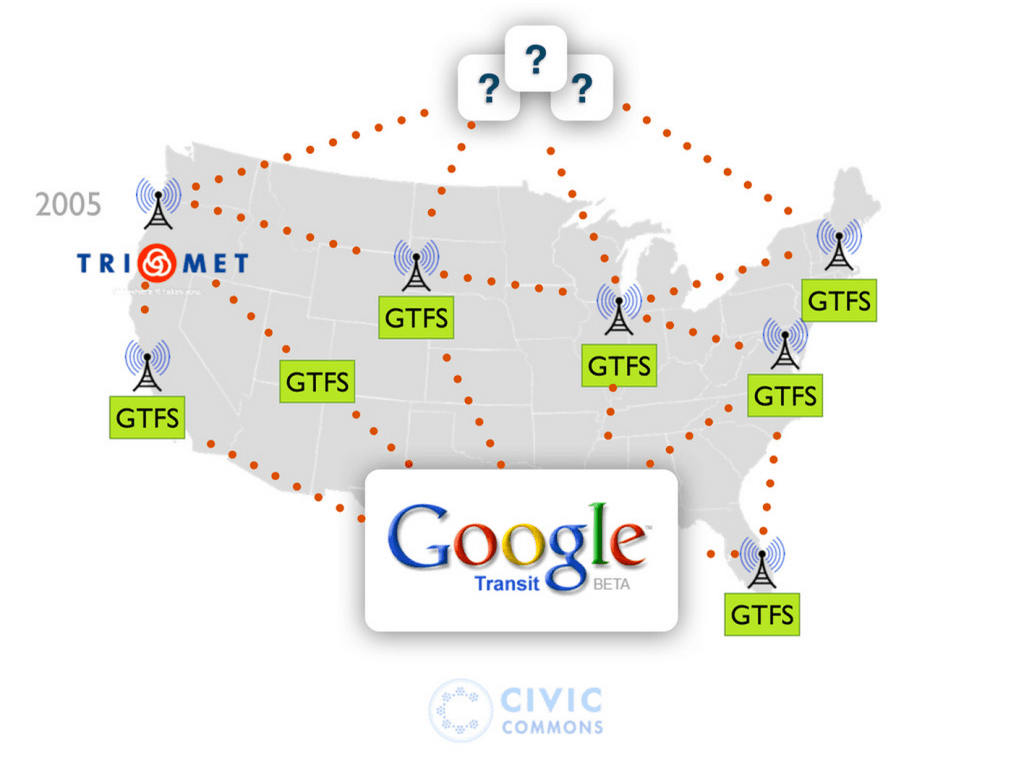
I mentioned the GTFS standard, which is now the primary way transit agencies publish route, schedule and real-time data. GTFS came to be because of work between Google and Portland’s Tri-Met back in 2005, as their collaboration to get Portland’s transit data into Google maps – so they created a lightweight standard as part of that. Then, Google used “hey, don’t you want your data in Google maps?” as the happy magnet, to draw other agencies (often VERY reluctantly) into publishing their data in GTFS as well. Here’s a diagram I made back in 2010 to tell this story:
This approach includes elements of the Brute Force approach — you need to have outsized leverage / distribution to pull this off.
It’s also worth noting that GTFS won the day (handily) vs. a number of similar formats that were being developed by the formal consortia of transit operators. I remember talking to folks at the time who had been working on these other standards, who were pissed that Google just swept in and helped bring GTFS to market. But that’s exactly the point I want to make here: a path to market is often more is more important than a perfect design.
The Awesome Partner Approach
Not really knowing the whole story behind Creative Commons, it seems to me that one of the huge moments for that project was their partnership with Flickr to bring CC licensed photos to market — giving photographers the ability to tag with CC licenses, and giving users the ability to search by CC.
CC was a small org, but they were able to partner with a large player to get reach and distribution.
The Make-them-an-offer-they-can’t-refuse Approach
Blockchain hacker Matan Field recently described the two big innovations of bitcoin as 1) the ledger and 2) the incentive mechanism. The incentive mechanism is the key — bitcoin and similar cryptoequity projects have a built-in incentive to participate. Give (compute cycles) and get (coins/tokens).
While the Bitcoin whitepaper could have been “just another whitepaper” (future blog post needed on that — aka the open standards graveyard), it had a powerful built-in incentive model that drew people in.
The Bottom-up Approach
At our team meeting on Monday, we got to discussing how oAuth came to be. (for those not familiar, oAuth is the standard protocol for allowing one app to perform actions for you in a different app — e.g., allow this app to post to twitter for me, etc).
According to the history on Wikipedia, oAuth started with the desire to delegate API access between Twitter and Magnolia, using OpenID, and from there a group of open web hackers took the project on. First as an informal collaboration, then as a more organized discussion group, and finally as a formal proposal and working group at IETF.
From being around the folks working on this at the time, it felt like a very organic, bottom-up situation. Less of a theoretical top-down need and more of a simple practical solution to a point-to-point problem that grew into something bigger.
The Pretty Pretty Please Approach (aka the Herding Cats Approach)
This one is hard. Come up with a standard, and work really hard to get everyone to agree that it’s a good idea and adopt it. It’s not impossible to do this, but it’s not easy.
This is more or less the approach we took back in 2009-12 with Open311. In 2009, John Geraci from DIYcity (a civic hacking community at the time) wrote a letter to Mayor Bloomberg suggesting NYC take an open approach to its 311 system (I worked on the letter with John, as did several of my colleagues at the time). From there, Philip Ashlock from OpenPlans took the lead on turning it into a real thing — working doggedly for 2 years with cities across the US, technology vendors large and small, and adjacent orgs like Code For America, to develop the specification and get it deployed. As of 2012, there were something like 50 cities and 10 vendors live on the standard. I would say that Open311 never had the “slingshot” or “magnet” it really needed to become huge and impactful — it was more of a slow grind. But Phil in particular gets tons and tons of credit for making it happen.
And…?
In thinking about this, I also looked into the history of foundational web standards like HTTP and SMTP.
Here is Tim Berners-Lee’s original concept for an online hypertext system, and here is his more formal proposal to his bosses at CERN to fund initial work on the project. He asked for $50k in manpower and $30k in software licenses. Glad his bosses gave him the green light!
Here is John Postel’s original proposal for SMTP (the primary protocol behind email) to the IETF networking group.
I honestly don’t know the politics of how either of these went from whitepaper to real, and I’d love to hear that story from anyone who knows.
Another good story is HTML5, which was begun by a splinter faction away from W3C (dodging the slow process there and the focus on XHTML), and then eventually merged back into the formal W3C process.
One lesson
One big takeaway I’ve had from working on all of this is that these things take time, and that if you’re playing the open standards game, you need the ability to be patient (in addition to having a clever go-to-market hack). It’s difficult to push a standard on a startup timeline. You’ll notice that many the historical players here had full-time employers (CERN, Google, universities, etc) that gave them the stability they needed and the flexibility to devote time to this sort of project.
And to reiterate the main point here — when looking at emerging standards and protocols, we’ve got to focus on the question “how do we get there”, and think hard about which go-to-market strategy to take.
// P.S., for a funny and slightly NSFW twist on this, see this post about the book “Where Did I Come From?” which I thought of when writing this post — my parents definitely read me that book when I was a kid and it made an impression.
Maybe we all live in the email anti-Lake Wobegon, where we’re all “worse than average” at email, in our own minds.
One problem with email is the giant guilt pile it creates — the psychological consisting of the number of emails you know are in there that you have forgotten about, ignored, or missed. My guess is that there’s actually a disconnect with the *actual* problem in your inbox and the size of the guilt pile, as much of what’s in there is probably out of date or irrelevant anyway. But nevertheless the guilt pile persists, and only grows.
I do my best to tackle this. I try and respond to short emails in-the-moment as much as possible, and I star things that require a more thoughtful response, and work through my starred box regularly. Recently, I started using Zirtual, and my new virtual assistant Michelle is handling all of my scheduling emails — that helps a LOT. But still, the guilt.
And, on the flip side: it sucks when people don’t respond to your emails. Especially when it’s someone or something you care about, and that message can leave you wondering: “did they miss this or am I a loser?”
So, here’s one idea for a solution, inspired by Joel’s text-me footer: an auto-apology email bot that periodically scans through my inbox and sends an apology to everyone who has a lingering message with me. The apology would say something like:
“hey — I’m really sorry but it looks like I’ve gone and ignored/missed/forgotten your email. I suck at email and it kills me. Here are the messages in my inbox that I haven’t responded to in the last [7|14|30] days: {list of email subjects} If anything in there is really important, please respond here and I promise I’ll get back to you.”
Perhaps this is impersonal and robotic, and it’s clearly not as good as me actually responding to your email the first time around, but wouldn’t it be an improvement?
I am in Paris this week for OuiShareFest, and spoke yesterday morning during the opening session. OuiShareFest is in its third year as a large international gathering of folks interested in the peer/collaborative/sharing/networked society, put on by the community organization OuiShare.
The topic of this year’s fest is “lost in transition”, and the prevailing feeling from the community here is a growing concern about the relationship between peer economy platforms and participants, specifically regarding distribution of value, control, etc. This is not really a big surprise, given the huge financings and staggering valuations that many corporate platforms in this space are putting up.
So, whereas I gather that the tone of the first OuiShareFest in 2012 was unabashedly glowing about the peer economy in all its forms, this year’s fest is much more pensive and reflective about the power dynamics built into web platforms, and in particular their relationship to established power in the form of capital investment.
For my talk, I wanted to take this issue head on, place it in a historical perspective, and help people think practically about what might come next and how to get there.
I’ll give a condensed, annotated version of the talk here:
The title “venture capital vs community capital” is an intentionally provocative strawman. The point I want to make is that of course there is a natural tension here, but it’s not a brand new dynamic, an either/or choice, or a zero-sum game.
Rather, it’s part of a recurring pattern that we can see dating back decades (if not much longer) in the history of technology. Viewed this historical lens, we can see the patterns of this cycle and use them to help us understand where the viable opportunities will be in this phase.
But first, I want to point out that the reason we’re all here is that we believe in the power of networks — of the connected society — to expand knowledge, deliver economic opportunity and solve big problems (energy, health, education, etc) in ways that haven’t been possible previously.
Right before my talk at OuiShareFest, Robin Chase went on and made a compelling plea for us to come up networked, scalable solutions (both venture-backed and community-backed) to the biggest issues facing the planet today, her biggest one being climate change. I am a firm believer that this model will continue to have profound, deep impacts on how we live, how we work, how we learn, and what we make, and that we are still in the very early stages.
But, as we become more and more familiar with this model, we’re starting to pay more attention to the particular architecture of these networks, and the power dynamics built into them.
1/ The Problem (opportunity)
So, the problem that many in this space have identified is a growing concern about the imbalance of power between peer economy platforms and the participants they support, especially as the most mature platforms (Airbnb and Uber being the elephants in the room, but there will be many more) grow to be very large, wealthy and powerful companies.
The problem is essentially one of trust. And specifically in the case of peer economy platforms and workers, it’s about economics and control. One way to think about this is that as this space has matured, platforms have a tendency to “thicken” — to do more, take more, and exert more control. So the question becomes, are participants here getting a fair deal, and do they have an appropriate amount of freedom and control? There is a growing sense that they may not be, and that alternative architectures need to be investigated.
While this may feel scary to many observers of the space, especially those coming at this from a public interest perspective, we shouldn’t be surprised to see this happen. Rather, this is what always happens as companies explore new spaces and establish profitable business models.
So rather than look at this phenomenon simply as a brand new problem to be solved today, it’s more useful to see it as yet another phase in a recurring cycle, that presents both known challenges and known opportunities.
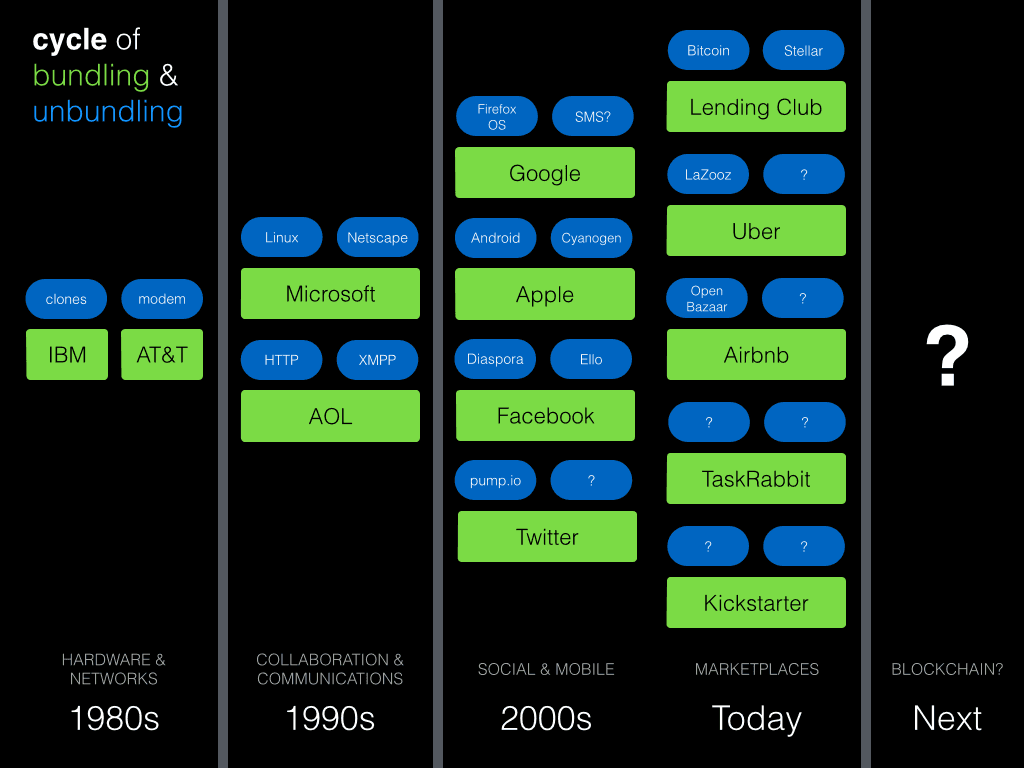
Looking back at the history of major tech platforms over the past 30 or so years, we can see this cycle turn (note: this is not intended to be exhaustive or complete):
(Note: the green boxes are companies, and the blue bubbles are “open” technologies like free software and open protocols — i.e., venture capital and community capital, respectively)
IBM and AT&T once had a monopoly on the PC and the telephone network, respectively, which was opened up by the PC clones and the modem going over-the-top of the telephone network (not to mention the government break-up of AT&T).
Next, Microsoft had a lock on PC software through Windows and Office, and AOL (along w Prodigy, Compuserve, etc) had the online market locked down. This lasted until the proliferation of Linux and IP protocol stack, which poked a hole in Microsoft’s desktop OS as well as AOL’s walled garden, giving us the open internet.
Then, on top of that newly open platform, today’s leaders in web (Facebook, Google, Amazon, Twitter, etc) and mobile (Apple, Google, Xaomi) built their businesses. It’s worth noting that, with the exception of Android, there hasn’t been a really meaningful hole poked in the business positions staked out by this generation of companies (though there have been attempts, such as Diaspora for Facebook and Pump.io for Twitter)
Finally, we’re left with today’s peer/sharing/collaborative economy marketplace platforms. These are the new, venture-backed companies staking out territory and building what will become the next generation of powerful incumbents. And while we have seen the beginnings of open protocols that directly challenge their power (like the La’Zooz ridesharing protocol), it’s all very very early.
So there’s the pattern: tech companies build dominant market positions, then open technologies emerge which erode the the tech companies’ lock on power (this is sometimes an organizedrebellion against this corporate power, and is sometime more of a happy accident). These open technologies then in turn become the platform upon which the next generation of venture-backed companies is built. And so on and so on; rinse and repeat.
So, all that is to say: this is not a new thing. And that seeing this as part of a pattern can help us understand what to make of it, and where the next opportunities could emerge.
Given this moment in the cycle — where we have a small number of large and powerful platforms in some sectors, and a growing sense of discomfort about that power — how might people who affect change go about doing it?
In this section, I want to really stress the “how do you get there part” more than the “what might an alternative architecture look like” part. It’s quite easy to imagine a “driver-owned uber” (as many people here have suggested) in its fully realized form, but it’s much more difficult to think about how such a thing might come into being. The history of technology is strewn with failed attempts to replace closed/proprietary systems with open ones.
Here, I’ll point out four ideas that may be helpful in thinking about this:
“Convenience trumps just about everything” — Steve O’Grady, analyst at Red Monk (link)
Today at OuiShareFest, Aral Balkan from Ind.ie talked about a major failure of the open source movement over the past several decades: to sacrifice short-term usability and experience for long-term (and abstract to most people) freedoms. He framed this problem as “respect for experience” and “respect for utility” (or something along those lines) as the two partner values along with respect for human rights. I would agree with that, and anyone following this space can note the failure of past attempts at open platforms that just weren’t usable enough (for example: openID).
“The Lindy Effect is real. Disruption is rare. But it does exist and it is caused by non-linear changes in technology.” — Albert Wenger, USV (link)
My colleague Albert discusses the Lindy Effect: the idea that every day that a platform idea exists extends its expected overall lifespan. In other words, technologies and ideas have momentum — the longer they’re around the longer they’ll stay around. It is possible to “disrupt” them, but that requires a profound, non-linear technology change. And even then, they don’t just disappear overnight. For example, Microsoft has endured two decades of disruption from the web — first against Windows as the dominant OS, and then against Office as the dominant productivity suite — but it still alive and kicking. So the disruption that challenged Microsoft didn’t put them out of business, but it did open up the market for many many many others to enter. Looking at today, Uber clearly isn’t going anywhere, though “open” challenges to them could open up the market for others.
To my mind the non-linear change in technology that has the greatest potential to challenge today’s incumbent platforms is the Blockchain (and related decentralized technologies) that are in the process of externalizing data from web and mobile applications (more on that below).
“Your margin is my opportunity” — Jeff Bezos
This profound idea is not new to the business world, but it’s nevertheless instructive for new technologies looking to compete against the new incumbents. Along the lines of “convenience trumps everything”, cost matters. For example, I met a blockchain entrepreneur/hacker recently who was incensed about the margin that Etsy takes on transactions (and to most people Etsy is about as fuzzy bunny as you can get as a large web platform).
“The first transaction in a block is a special transaction that starts a new coin owned by the creator of the block” — Satoshi Nakamoto (link)
This is a line from the original Bitcoin white paper, and I include it to point out the importance of powerful incentives in deploying open technologies. There are two primary innovations in Bitcoin: 1) the distributed, open ledger; and 2) the financial incentive that drives participating computers to cooperate: mining bitcoins.
To the extent that this incentive-to-cooperate model can be extended in other directions, we may be on to something big.
3/ What we’re looking for
Given all of the above, here are a few things we’re looking for at USV:
Collaborative platforms in greenfield sectors
To the first point about the value of networks (to society), there are many many important sectors still operating under inefficient bureaucratic hierarchical models, which are ripe to be re-architected in a network model (I’m thinking energy, health, education, and many others).
I suspect that these sectors will be developed by “traditional” networks (e.g., venture-backed, centralized networks), as these have the ability to move the most quickly, to experiment with new models (failing often), and to help train sectors/cultures that a networked model is possible.
Worker support services
A major concern with the emerging power of web platforms (especially in the collaborative/sharing space) is worker power. We are already beginning to see platforms emerge to serve workers in this environment (e.g., SherpaShare, Coworker, Peers, the venerable Freelancers Union, etc) and will see many many more here.
My belief is that “union 2.0” will be a platform, more than an organization, and its power will derive from the data leverage it’s able to attain over the the platforms that employ its workers.
Thin platforms
One way to challenge “thick” platforms is to build “thin” platforms that do less, take less, and exert less control. We have invested in several of these (DuckDuckGo, compared to Google, Twitter, compared to Facebook, Sidecar compared to Lyft, etc) and are looking for more. Often times, “thin” also means decentralized in some way, pushing power, economics and control further out to the edge.
New protocols
Finally, new protocols that radically re-architect power, information and control. Inspired by Bitcoin and the blockchain, there is now tremendous energy in this space. It’s early early days, but it does feel like this has the potential to become the next “open layer” that washes over the latest generation of big companies (see the diagram above) and cracks open the market even further.
At USV, we’ve made several small investments in this space (OneName, and two that are not yet announced), and are looking for more. It’s not clear yet where value will accumulate at this layer, and much of it may and should remain as “community capital” in the system.
In conclusion: we are at a really interesting time with the maturity of the large web and mobile platforms, the rapid expansion of peer/sharing/collaborative platforms, and the emergence of distributed protocols. All of this has raised really interesting questions about innovation, global problem-solving, economics and control, and the discussion here will undoubtedly lead to short- and long-term impacts on how and what we build.
A while back, I wrote about Anti-Workflow Apps — apps that solve problems for you without forcing you to adopt a workflow that you may never fully be able to adopt. Workflow apps (CRMs, to-do lists, project management tools) are super hard to drive adoption towards, as everyone works differently and really resists this kind of change. (of course, it’s possible when the reward is super good — e.g., slack and git/github — bit those times are rare and more often than that an attempted re-workflow goes splat)
So I’ve been on the lookout for Anti-Workflow tools. Solutions that solve a problem that you think requires a new workflow, but may actually be more effectively solved another, more clever way Today I want to talk about to-dos, because I seem to have found my own personal anti-workflow solution.
I’ve always struggled with to-dos — I’ve used every to-do management tool on earth, and have never been able to adopt a workable, effective system. I’ve tried everything from complicated tracking systems like OmniFocus to simple to-do lists of every possible flavor. Nothing has stuck. For years and years, I kept trying, trying and trying again.
In the end, I just gave up and said, fuck it, I’m not using a to-do list anymore. Not going to even try.
What happened was that I ended up keeping track of my priorities in a totally different way — a way that was actually more in tune with my existing workflows. One part of the solution was pretty obvious, and one was surprising.
On the obvious side: the calendar. For things that I absolutely must do, and that require dedicated time, I just use my calendar. I’m in my calendar all day long, so it’s the perfect place to block out time for important things. So now I set calendar entries for myself, to make sure I set aside time for things that need focus.
The calendar is good for things I know I need to do, and that I know are important. What it’s not good for is capturing notes, ideas, and small to dos, which often just need to be captured in the moment and prioritized & dealt with (or not) later. This is the use case that has always drawn me back to to-do apps, to no avail.
In particular, the really bad thing about a to-do list for this use case is that all it does is make you feel guilty. Items get added to the list, and whether you really need to do them or not, you feel drawn to. And then when it doesn’t happen the to-do list just becomes a giant pile of guilt that you do your best to ignore (that’s what happens to me at least).
That brings us to the less obvious solution. What I’ve found is that a great way to handle both the capture / prioritization issue and the guilt issue is to use a Sparkfile. Long time readers will know that this blog is named after my favorite idea from Steven Johnson’s Where Good Ideas Come From: the “slow hunch” approach to developing ideas. Another idea from that book — unearthed by studying epic thinkers of the past like Darwin and DaVinci — is the Sparkfile: a long, running list of thoughts & ideas. Fragments that pile on one another over time. One way to cultivate the slow hunch is not only to keep a sparkfile (in addition to other kinds of journals), but to constantly pour back through it re-reading and reconsidering your previous thoughts, ideas and observations.
Turns out that this is also a pretty good way to filter inbound ideas of things to do. Just add them to the spark file, continually review the list, and occasionally do things (immediately or via calendar), and then add new stuff to the top as you think of more things. No pressure — and absolutely no expectation — to do everything on the list or turn it into a perfect set of priorities. Just let the mind run, capturing as you go.
For me, this idea ties back into anti-workflow because I’ve been keeping a personal blog/journal for about 7 years now. Which was in many ways a sparkfile, though it started out slightly more long form (starting with a private wordpress blog). The big revolution happened last fall, when I switched over to using Diaro. Diaro is a personal journal tool, with both a desktop web client as well as a mobile app. The mobile app is the key, as it makes it possible to really quickly jot down a thought — as quickly as you’d do on a to-do app, or email, or notepad.
So in the end, the solution to my to-do workflow was not to add a new to-do workflow. Rather, it was to extend the workflows I already had going, calendars and the sparkfile. Boy it feels good.